CS61b_Lec19_Hashing
理解hash table,让我们从最简单的开始:
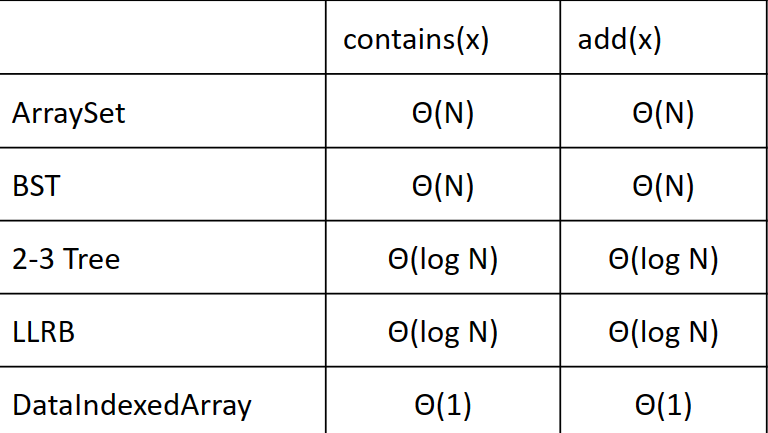
DataIndexedArray
Create an array of booleans indexed by data! - Initially all values are false. - When an item is added, set appropriate index to true. 添加了0、5、10在这个DataIndexedArray里:
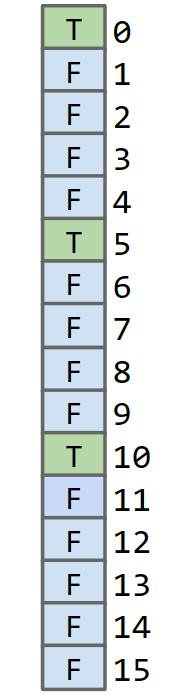
如果用这样的数组来存数据的话,仅仅是存数字就需要很多空间,并且还很浪费,而且一些其他的数据,比如字符串,汉字这些没法存,虽然它很快:
接下来我们继续改进: 开始存字符串进去,比如cat、dog这些,数字是本身就是index,而字符串如果只是用首位的话就很容易产生冲突 --- cat存第三个,那我cap存第几个呢?
Avoiding Collisions
Use all digits by multiplying each by a power of 27.
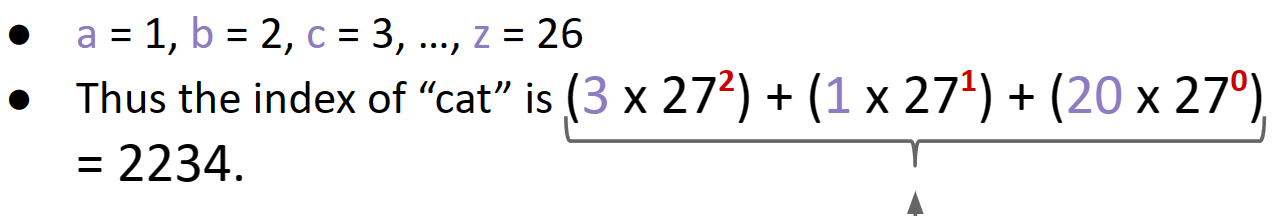 这种算index的方法和进制很像:
这种算index的方法和进制很像:
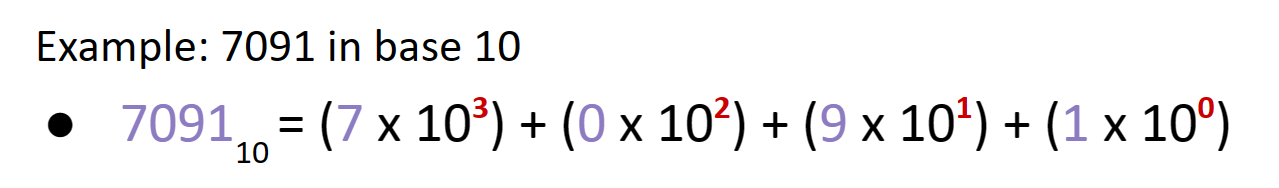
上面只存了小写字母,非常受限,我们再一次改进:
先引入ascii的概念,第33 - 126位是可见字符,超出ascii就是unicode了,扩大基数(base)
举例一个中文短语编码(unicode)
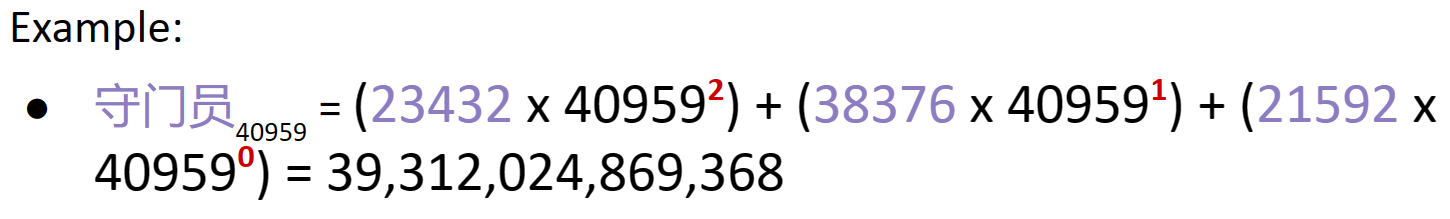
Integer Overflow
数的大小有限制,超出则会溢出,这就导致可能会有两个算出来是一样的index,就是冲突:

(箭头那里是返回true了)
Overflow can result in collisions, causing incorrect answers.
引入Pigeonhole Principle: 大致意思是十个鸽子放入九个笼子中,必定有一个笼子有两只鸟(每个笼子都需要有鸽子) 潜在哈希冲突:项目数量超过了哈希函数的输出情况 Pigeonhole principle tells us that collisions are inevitable due to integer overflow冲突无法避免
那么: - 如何解决哈希冲突(collision handling) - 如何计算任意一个object的哈希码?(computing a hashCode)
Make a Bucket
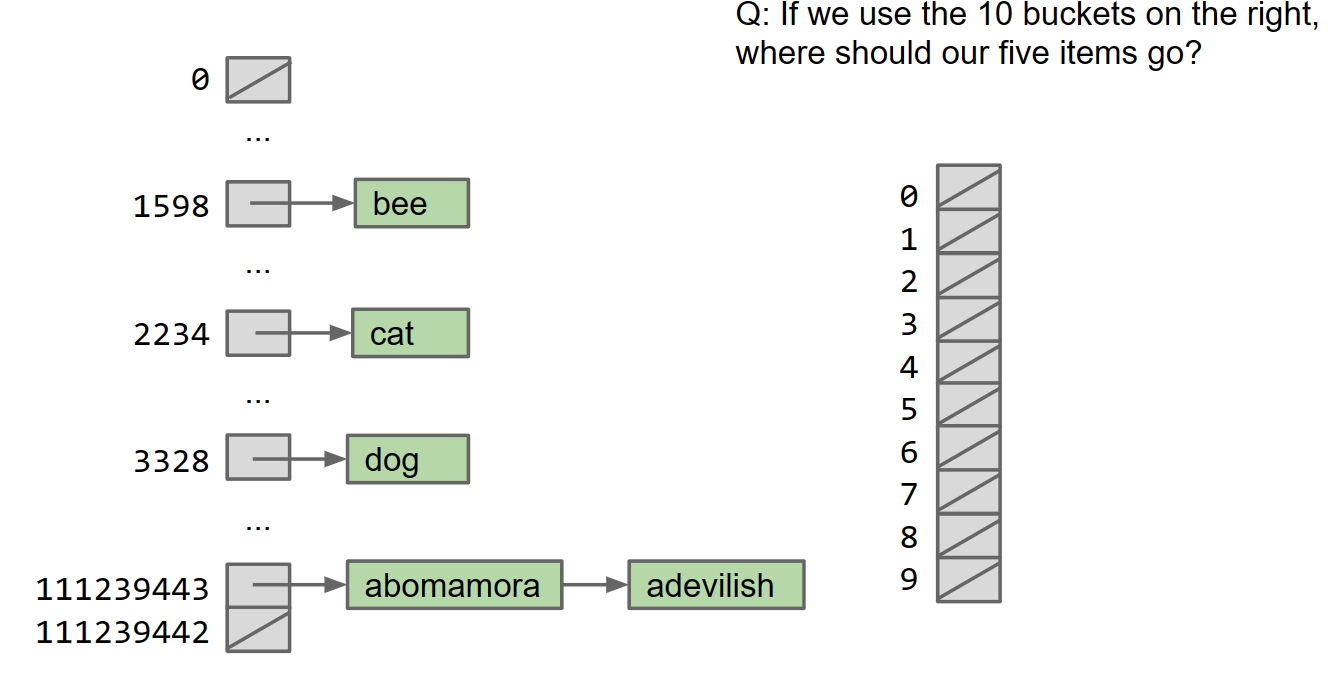
别急,接着继续改进: Suppose N items have the same numerical representation h: - Instead of storing true in position h, store a “bucket” of these N items at position h.
How to implement a “bucket”? - Conceptually simplest way: LinkedList. - Could also use ArrayLists. - Could also use an ArraySet. - Will see it doesn’t really matter what you do. bucket本身的性质并不重要
有冲突的话直接全塞进原地,hash table初具雏形
但是我们不需要这么长的list,so looong 的bucket,这不跟链表没差吗。 答案是模,把长长的bucket斩断分到其他bucket里去
Hash Table
然后 hash table上场!!
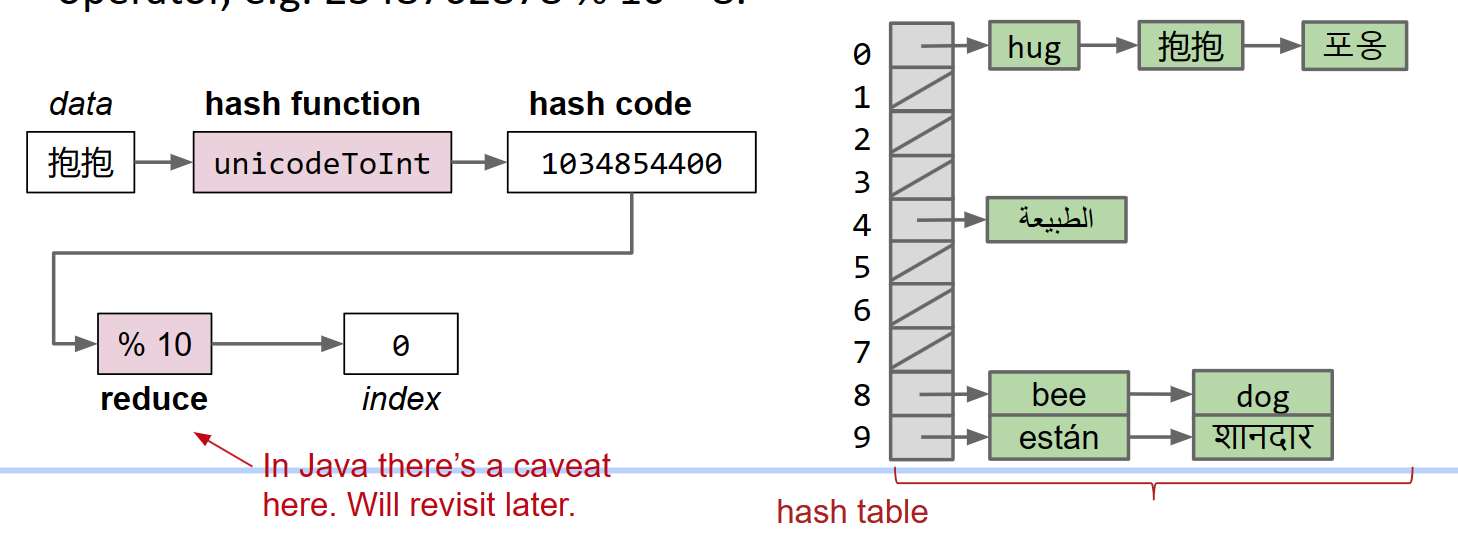
- Data is converted by a hash function into an integer representation called a hash code.
- The hash code is then reduced to a valid index, usually using the modulus operator, e.g. 2348762878 % 10 = 8.
Hash Table Runtime
- The good news: We use way less memory and can now handle arbitrary data.
- The bad news: Worst case runtime is now Θ(Q), where Q is the length of the longest list.
find x的算法scale:

Load factor
这样显然不太行,都N了你还不如直接上链表呢,继续改进:
Suppose we have:
- An increasing number of buckets M.
- An increasing number of items N.
As long as M = Θ(N), then O(N/M) = O(1).
N在变大的同时,bucket的数量也跟着大,相比一除就是1了,之前那个bucket定死的是N/5,不就是N。实现的大致方法是判断N/M的比值,比如 > 5时M double一下,这里的比值就是下面的load factor
Even distribution of item is critical for good hash table performance.
- Both tables below have load factor of N/M = 1.
- Left table is much worse!
- Contains is Θ(N) for x.
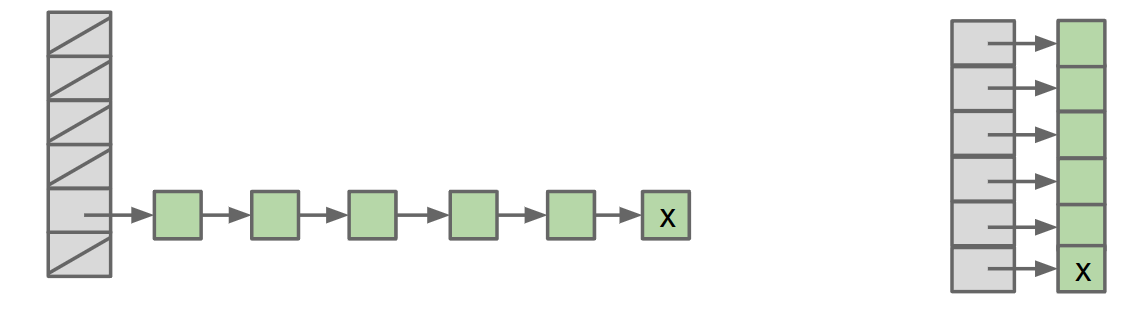
- Contains is Θ(N) for x.
Default implementation simply returns the memory address of the object. Java里面默认的hashcode就是返回当前object的地址,这个方法真聪明。
Warning
- Never store objects that can change in a HashSet or HashMap!
- Never override equals without also overriding hashCode.